说明文档
vit-base-nsfw-detector
该模型是基于 vit-base-patch16-384 在约 25,000 张图片(绘画、照片等)上微调而成。 它在评估集上取得了以下结果:
- 损失:0.0937
- 准确率:0.9654
<u>新增 [07/30]</u>:我创建了一个专门用于检测 Stable Diffusion 图像的 NSFW/SFW 图像的 ViT 模型(请阅读下面的免责声明了解原因):AdamCodd/vit-nsfw-stable-diffusion。
免责声明:这个模型并不是为生成式图像设计的!训练数据集中没有任何生成式图像,而且该模型在生成式图像上的表现明显较差,这需要另一个专门针对生成式图像训练的 ViT 模型。以下是该模型在生成式图像上的实际表现:
- 损失:0.3682(↑ 292.95%)
- 准确率:0.8600(↓ 10.91%)
- F1:0.8654
- AUC:0.9376(↓ 5.75%)
- 精确率:0.8350
- 召回率:0.8980
模型描述
Vision Transformer(ViT)是一种 Transformer 编码器模型(类似 BERT),是在大量图像上以监督方式预训练的,即 ImageNet-21k,分辨率为 224x224 像素。随后,该模型在 ImageNet(也称为 ILSVRC2012)上进行了微调,这是一个包含 100 万张图像和 1000 个类别的数据集,分辨率更高,为 384x384。
预期用途与限制
有两个类别:SFW(适合工作场所)和 NSFW(不适合工作场所)。该模型经过训练会偏向于严格分类,因此会将"性感"图像归类为 NSFW。也就是说,如果图像显示乳沟或露出过多皮肤,它将被归类为 NSFW。这是正常现象。
本地图像使用方法:
from transformers import pipeline
from PIL import Image
img = Image.open("<path_to_image_file>")
predict = pipeline("image-classification", model="AdamCodd/vit-base-nsfw-detector")
predict(img)
远程图像使用方法:
from transformers import ViTImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('AdamCodd/vit-base-nsfw-detector')
model = AutoModelForImageClassification.from_pretrained('AdamCodd/vit-base-nsfw-detector')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: sfw
使用 Transformers.js(原生 JavaScript):
/* Instructions:
* - Place this script in an HTML file using the <script type="module"> tag.
* - Ensure the HTML file is served over a local or remote server (e.g., using Python's http.server, Node.js server, or similar).
* - Replace 'https://example.com/path/to/image.jpg' in the classifyImage function call with the URL of the image you want to classify.
*
* Example of how to include this script in HTML:
* <script type="module" src="path/to/this_script.js"></script>
*
* This setup ensures that the script can use imports and perform network requests without CORS issues.
*/
import { pipeline, env } from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.1';
// Since we will download the model from HuggingFace Hub, we can skip the local model check
env.allowLocalModels = false;
// Load the image classification model
const classifier = await pipeline('image-classification', 'AdamCodd/vit-base-nsfw-detector');
// Function to fetch and classify an image from a URL
async function classifyImage(url) {
try {
const response = await fetch(url);
if (!response.ok) throw new Error('Failed to load image');
const blob = await response.blob();
const image = new Image();
const imagePromise = new Promise((resolve, reject) => {
image.onload = () => resolve(image);
image.onerror = reject;
image.src = URL.createObjectURL(blob);
});
const img = await imagePromise; // Ensure the image is loaded
const classificationResults = await classifier([img.src]); // Classify the image
console.log('Predicted class: ', classificationResults[0].label);
} catch (error) {
console.error('Error classifying image:', error);
}
}
// Example usage
classifyImage('https://example.com/path/to/image.jpg');
// Predicted class: sfw
该模型在各种图像(写实、3D、绘画)上进行了训练,但它并不完美,有些图像可能会被错误地归类为 NSFW。此外,请注意,在 transformers.js 管道中使用量化后的 ONNX 模型会略微降低模型的准确率。 您可以在此处找到使用 Transformers.js 的该模型的玩具实现 here。
训练与评估数据
需要更多信息
训练过程
训练超参数
以下超参数用于训练:
- 学习率:3e-05
- 训练批量大小:32
- 评估批量大小:32
- 随机种子:42
- 优化器:Adam,betas=(0.9,0.999) 和 epsilon=1e-08
- 训练轮数:1
训练结果
- 验证损失:0.0937
- 准确率:0.9654
- AUC:0.9948
混淆矩阵(评估):
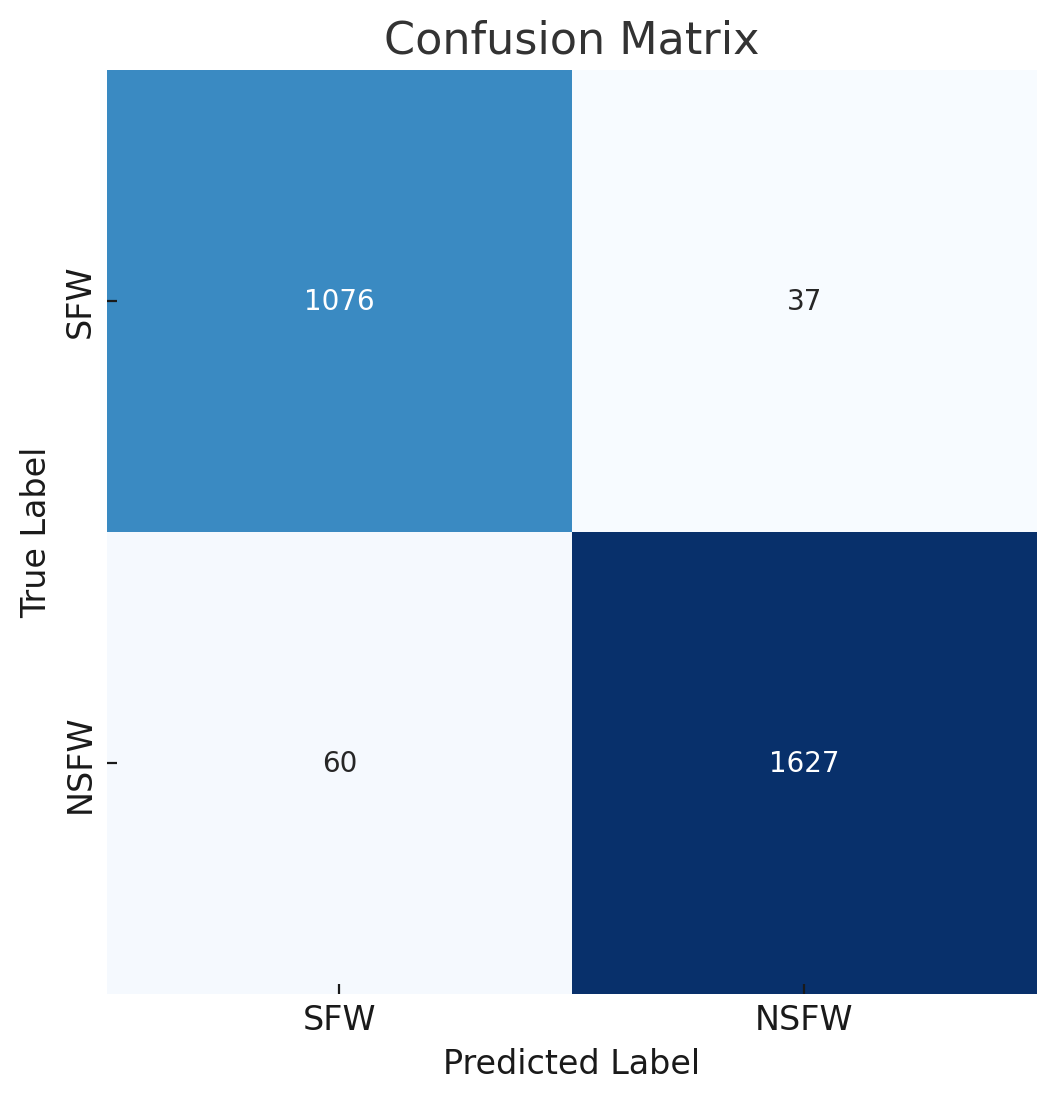{kind=link}
[1076 37]
[ 60 1627]
框架版本
- Transformers 4.36.2
- Evaluate 0.4.1
如果您想支持我,可以在这里。
AdamCodd/vit-base-nsfw-detector
作者 AdamCodd
创建时间: 2024-01-03 20:10:17+00:00
更新时间: 2024-12-03 14:14:31+00:00
在 Hugging Face 上查看