说明文档
animeGender-dvgg-0.8
-
一款用于动画角色性别分类的尖端轻量级模型集。
-
更新信息:该模型是我们之前分类模型 animeGender-dvgg-0.7 的更新版和升级版,具有以下描述的新功能和能力。
描述
-
我们提出的模型 animeGender-dvgg-0.8,是由 DOF-Studio(2023)创建的二分类模型,基于著名的 resnet 结构(而在之前的版本中,我们使用的是 vgg 结构),旨在识别特定动画角色的性别(专为日式2D动漫角色设计)。该模型由 DOF-Studio 于2023年7月训练,使用的是由我们员工手动收集和标注的扩展组织私有数据集。在我们之前的测试中,这个版本的 animeGender 模型系列在我们的测试集、验证集,甚至一个专门设计的压力测试数据集上,都展示了前所未有的无懈可击且令人惊艳的结果。
-
请注意,虽然这个模型仍然不是我们角色性别识别模型系列的最终版本,它只是我们开源项目的阶段性成果(0.8版本),这意味着我们的团队将在不久的将来发布升级版本,我们有信心地告诉大家,我们的目标是在通用性和功能性方面创建更复杂和智能的网络结构,而不仅仅是追求精度结果,因此即将发布的版本仍将有所改进。感谢大家对我们工作和模型的所有赞赏与支持。
重要特性
-
精度的巨大提升: 在外部验证数据集上达到整体96%以上的精度,该数据集包含约56,000个与训练数据集风格相似的动漫角色样本。 在一个极端设计的压力测试数据集上达到整体94%以上的精度,该数据集包含约1,200个风格完全不同且性别难以(但仍能)被肉眼识别的动漫角色样本。 我们坚信,这款凭借卓越精度和强大泛化能力的模型,已在开源模型中跻身顶尖行列,至少在主流平台上是如此。
-
确定性输出: 与其他性别检测模型不同,尤其是那些将 CONFUSE 作为可能输出之一的模型,我们的模型,或者说整个 animeGender 模型系列, 不会,也永远不会输出像 CONFUSE 或 UNKNOWN 这样模糊的标签。 鉴于有时角色的性别可能确实难以用肉眼辨别,我们将那些性别无法定义的样本从训练集中剔除。 因此,我们模型的结果显示的是一种概率,或者说是倾向性,即仅根据给定图像(而没有任何特定背景设定中的潜在信息),某个角色的性别可能是什么。
-
无需第二性征(SSE): 我们的模型使用完整的面部图像来识别角色的性别,输入模型所需的只是头部或包含部分头发的面部。 因此,使用本系列模型时,不需要全身图像,特别请注意只使用头部。 鉴于大多数插画图像自然具有可观察的性别指示特征,我们不使用第二性征来进行判断,而仅依靠面部特征。
-
跨越性技术: 我们使用了一种由团队发明的全新技术来手动控制训练过程,以改善过拟合问题并同时提升整体性能。 这项技术基本上可以理解为一种智能工具,帮助训练系统识别样本中的异常值,并尝试在训练时为其分配较低的权重来调整梯度。 显然,它对我们提出的模型性能有明显的提升,与对照组相比,它至少带来了1.5%的精度提升和2.0个点的泛化能力提升。
-
插画的通用性: 与上一代相比,这个版本 animeGender-dvgg-0.8 在多样化的训练数据集上进行了训练和调优,包含更多样化的风格、姿势和插画质量,因此也能够识别以不同表现形式呈现的更多角色的性别。 请注意,它仍然仅设计用于识别日式动漫角色,对线稿、真实图像和3D角色的性能不作保证。
-
多种选择: 与之前的版本不同,这一代我们同时发布了 animeGender-dvgg-0.8 模型系列的两种不同类型,即 animeGender-dvgg-0.8-alpha 和 animeGender-dvgg-0.8-beta。差异如下面第一张图表所示,它们通常设计用于不同的用途。 请注意,未来我们计划构建一个专门设计的模型结构,而不是使用现有的模型结构,希望能实现更先进的性能。 关于模型选择标准,这里有一个参考建议:
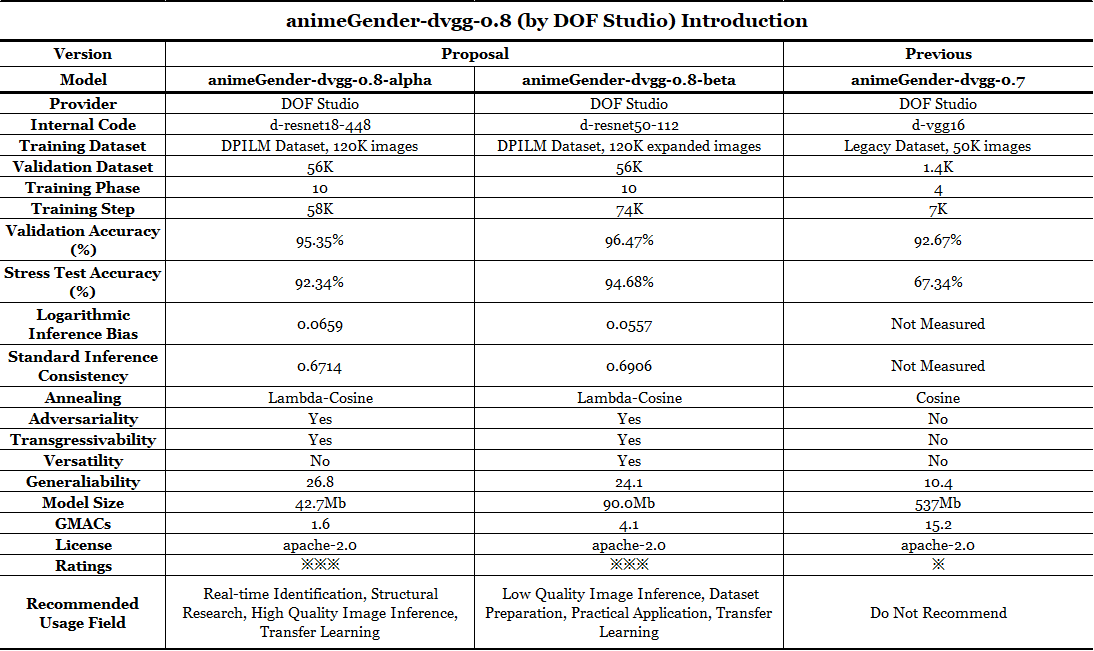
技术细节
-
修改:该模型 animeGender-dvgg-0.8 基于 resnet 结构,对最后的序列层(即全连接层)进行了修改,这意味着我们将其修改为二分类模型,有两个节点分别输出每种性别的可能性,即女性和男性。
-
输入:就像 resnet 的原始设计一样,其输入分辨率为224 * 224,RGB颜色空间为3个通道,在我们的模型 animeGender-dvgg-0.7 中,我们使用相同的维度(224 * 224,三个通道)。请注意,在将图片输入模型时,请确保输入的插画仅包含您想要识别的角色的头部和面部,以使模型的结果最精确可靠。
-
输出:该模型 animeGender-dvgg-0.8 的原始输出是一个长度为2的一维张量,分别显示输入每种结果的可能性,即女性和男性。在我们的开源使用示例中(见文件夹),我们已经方便地将原始输出转换为可读的结果,例如 "male",并附带一个显示可能性或置信度的数值。请注意,我们的模型不具有特定角色的背景知识或动画的上下文信息,因此一些中性角色可能仍会被错误分类,或者正确匹配但置信度在0.5左右。
-
检查点:我们为标记为 "alpha" 和 "beta" 的两种模型各提供了三种类型:".safetensors" 用于 Pytorch,".onnx" 用于实现,以及 ".pb" 用于 keras。您可以直接下载您感兴趣的某个模型和脚本文件 "use.py" 进行推理,无需完整克隆此仓库。由于训练过程中产生了大量阶段性检查点,我们不提供比所提模型性能较差的其他检查点。
结果与排名
- 这里有一张全面的表格展示了我们模型的结果和排名。

示例
-
以下是我们员工进行的一些样本外部测试及相应结果。请注意,我们使用与之前版本相同的遗留演示集来展示模型的性能和输出,这里有一张图表说明:

-
这里有一张简洁的图表展示了不同模型的性能,包括本仓库提出的模型和之前0.7版本的模型。

-
请注意,当您正常使用此模型时,性能基本处于我们的压力测试和验证范围之内。
使用方法
-
我们已将 Python 使用方法上传到文件夹中,请注意您需要下载它们并在本地使用 CPU 或 CUDA 运行。
-
在名为 "use.py" 的脚本中,您可以通过更改模型文件路径和图像文件路径在自己的设备上操作。该脚本支持 CPU 和 CUDA 推理,要在两种方法之间切换,只需在加载模型时更改一个布尔变量。
-
请注意,只有提供的代码才能被视为使用此模型的唯一推荐方法,而其他方式(包括本网站自动显示的方式)不保证有效且用户友好。
局限性
-
该模型擅长的风格范围仍然有限,几乎局限于现代日式插画,而线稿、美式动画则不支持。但请注意,虽然我们旨在提高此系列模型的通用性,我们从未计划将美式或韩式动画插画纳入我们的训练集,而是只专注于我们目前所做的事情。但对于任何感兴趣的人来说,这可能是一个机会,可以根据您的需求微调自己的模型,例如特定风格。
-
我们模型的精度与您输入的图像有关,这不仅意味着质量,尤其意味着面部在图像中的比例。我们假设每个人只关心角色面部的细节而不关心其他信息,并在我们的工作中这样做,因此,为了在使用我们的模型时保持高性能,我们强烈建议方形图像中至少80%应为角色的完整面部,否则,如果面部太小而无法包含足够的细节供模型识别,则无法保证性能。
-
由于男性角色的来源不足,男性的精度略低于女性。但我们正在努力寻找方法在未来的版本中解决这个问题。
注意事项
-
我们自信地声明,我们训练的所有数据都来自真人插画,但我们的模型也适用于生成图像,例如由 stable diffusion 生成的图像,并具有相对较高的准确性。
-
我们自信地声明,除了此 README.md 文件外,所有与模型相关的文件自首次发布以来永远不会更改,因此请关注并点赞我们以获取更新版本。
-
我们团队已经正式发布了能够出色完成此任务的新模型,请参考下面显示的链接:
-
0.9版本即将推出!请查看:https://huggingface.co/DOFOFFICIAL/animeGender-dvgg-0.9。
此致,
DOF Studio 团队,2023年8月1日
DOFOFFICIAL/animeGender-dvgg-0.8
作者 DOFOFFICIAL
创建时间: 2023-07-08 08:23:53+00:00
更新时间: 2023-08-04 02:27:22+00:00
在 Hugging Face 上查看