说明文档
OpenReasoning-Nemotron-1.5B 概述
描述:<br>
OpenReasoning-Nemotron-1.5B 是一个大语言模型(LLM),它是 Qwen2.5-1.5B-Instruct(也称为参考模型)的衍生版本。它是一个推理模型,经过后训练用于数学、代码和科学解决方案生成的推理。我们使用最多 64K 输出 token 对此模型进行了评估。OpenReasoning 模型提供以下尺寸:1.5B、7B、14B 和 32B。<br>
此模型可用于商业/非商业研究用途。<br>
许可证/使用条款:<br>
管理条款:上述模型的使用受 Creative Commons Attribution 4.0 International License (CC-BY-4.0) 管辖。附加信息:Apache 2.0 License
推理基准测试得分
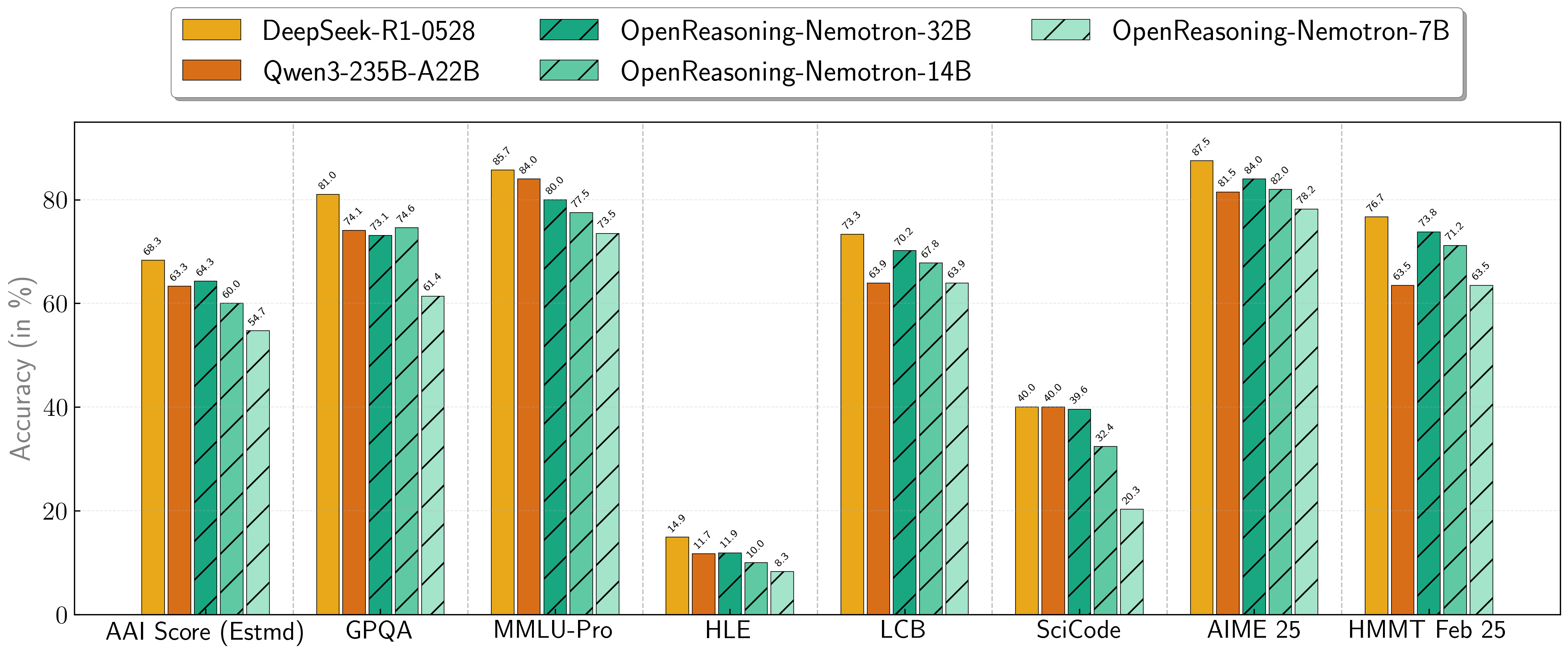
我们的模型在一系列具有挑战性的推理基准测试中展现出卓越的性能。7B、14B 和 32B 模型在其尺寸类别中持续创下新的最先进记录。
| 模型 | AritificalAnalysisIndex* | GPQA | MMLU-PRO | HLE | LiveCodeBench* | SciCode | AIME24 | AIME25 | HMMT FEB 25 |
|---|---|---|---|---|---|---|---|---|---|
| 1.5B | 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| 7B | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| 14B | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| 32B | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
* 这是我们对 Artificial Analysis Intelligence Index 的估算,非官方得分。
* LiveCodeBench 版本 6,日期范围 2408-2505。
结合多个智能体的工作
OpenReasoning-Nemotron 模型可以通过启动多个并行生成并通过 [生成式解决方案选择] 来以"重型"模式使用。为了添加这种"技能",我们遵循原始的 GenSelect 训练流程,但我们不训练选择摘要,而是使用 DeepSeek R1 0528 671B 的完整推理轨迹。我们只训练模型为数学问题选择最佳解决方案,但令人惊讶的是,这种能力直接泛化到了代码和科学问题!通过这种"重型" GenSelect 推理模式,OpenReasoning-Nemotron-32B 模型在数学和编码基准测试中超越了 O3 (High)。
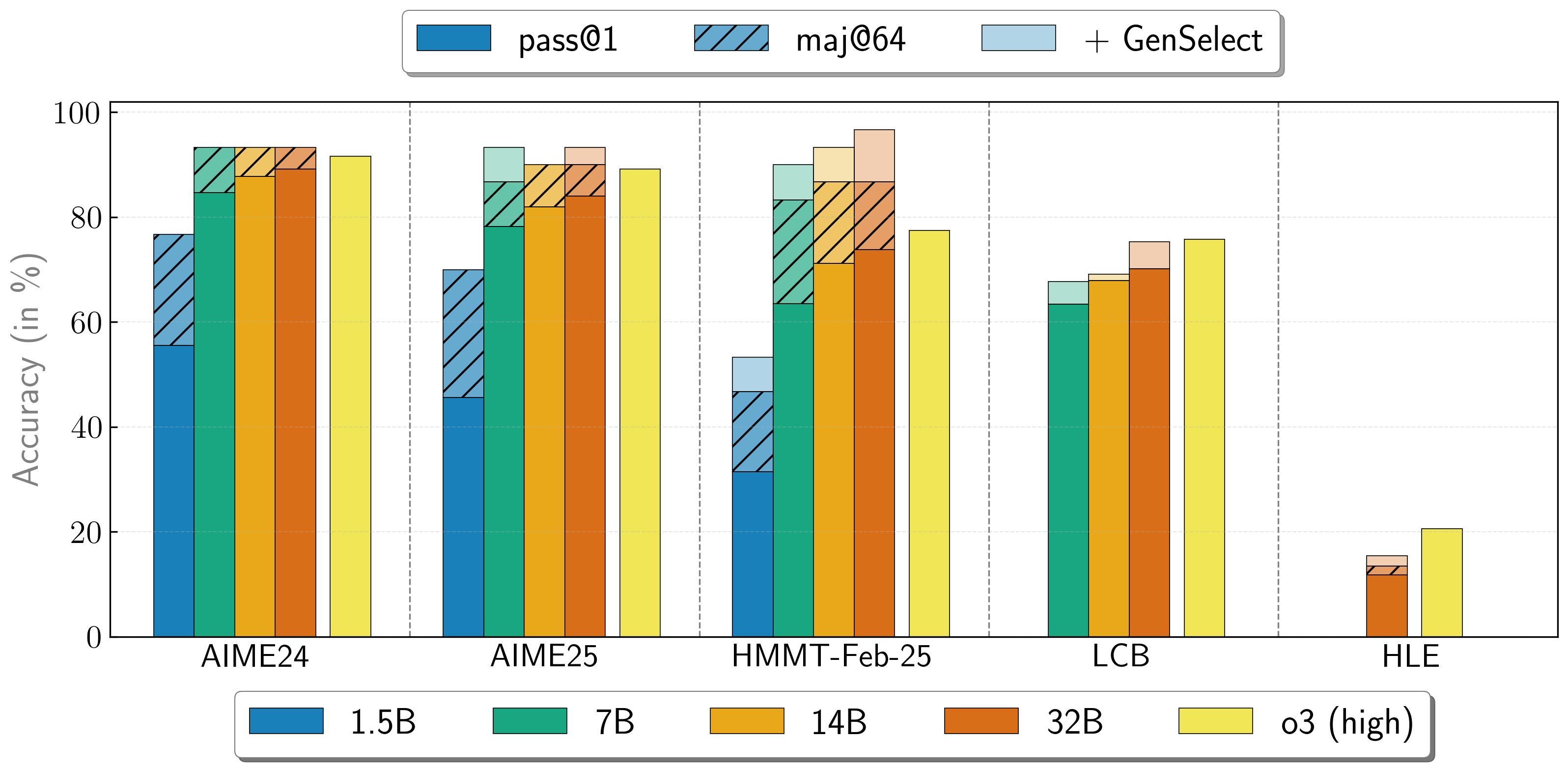
| 模型 | Pass@1 (Avg@64) | Majority@64 | GenSelect |
|---|---|---|---|
| 1.5B | |||
| AIME24 | 55.5 | 76.7 | 76.7 |
| AIME25 | 45.6 | 70.0 | 70.0 |
| HMMT Feb 25 | 31.5 | 46.7 | 53.3 |
| 7B | |||
| AIME24 | 84.7 | 93.3 | 93.3 |
| AIME25 | 78.2 | 86.7 | 93.3 |
| HMMT Feb 25 | 63.5 | 83.3 | 90.0 |
| LCB v6 2408-2505 | 63.4 | n/a | 67.7 |
| 14B | |||
| AIME24 | 87.8 | 93.3 | 93.3 |
| AIME25 | 82.0 | 90.0 | 90.0 |
| HMMT Feb 25 | 71.2 | 86.7 | 93.3 |
| LCB v6 2408-2505 | 67.9 | n/a | 69.1 |
| 32B | |||
| AIME24 | 89.2 | 93.3 | 93.3 |
| AIME25 | 84.0 | 90.0 | 93.3 |
| HMMT Feb 25 | 73.8 | 86.7 | 96.7 |
| LCB v6 2408-2505 | 70.2 | n/a | 75.3 |
| HLE | 11.8 | 13.4 | 15.5 |
如何使用模型?
在编程问题上运行推理:
import transformers
import torch
model_id = "nvidia/OpenReasoning-Nemotron-1.5B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
# 代码生成提示词
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use python programming language only.
You must use ```python for just the final solution code block with the following format:
```python
# Your code here
```
{user}
"""
# 数学生成提示词
# prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.
#
# {user}
# """
# 科学生成提示词
# 您可以参考此处的提示词 -
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (用于 GPQA)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
messages = [
{
"role": "user",
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
]
outputs = pipeline(
messages,
max_new_tokens=64000,
)
print(outputs[0]["generated_text"][-1]['content'])
我们在此仓库中添加了 一个简单的基于 transformer 的脚本 来演示 GenSelect。
要了解如何在 GenSelect 模式下使用 NeMo-Skills 模型,请参阅我们的 文档。
要使用 GenSelect 推理的模型,我们建议遵循我们在 NeMo-Skills 中的 参考实现。或者,您可以手动从所有解决方案中提取摘要,并使用这个 提示词 处理数学问题。我们将很快添加用于编程问题的提示词和参考实现!
您可以在以下论文中了解更多关于 GenSelect 的信息:
- AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
- GenSelect: A Generative Approach to Best-of-N
访问训练数据
训练数据已发布!数学和代码数据作为 Nemotron-Post-Training-Dataset-v1 的一部分提供,科学数据可在 OpenScienceReasoning-2 中获取。 更多详情请参阅我们的 文档。
引用
如果您发现这些数据有用,请引用:
@article{ahmad2025opencodereasoning,
title={{OpenCodeReasoning: Advancing Data Distillation for Competitive Coding}},
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
year={2025},
eprint={2504.01943},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.01943},
}
@misc{ahmad2025opencodereasoningiisimpletesttime,
title={{OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique}},
author={Wasi Uddin Ahmad and Somshubra Majumdar and Aleksander Ficek and Sean Narenthiran and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Vahid Noroozi and Boris Ginsburg},
year={2025},
eprint={2507.09075},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.09075},
}
@misc{moshkov2025aimo2winningsolutionbuilding,
title={{AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset}},
author={Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
year={2025},
eprint={2504.16891},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.16891},
}
@inproceedings{toshniwal2025genselect,
title={{GenSelect: A Generative Approach to Best-of-N}},
author={Shubham Toshniwal and Ivan Sorokin and Aleksander Ficek and Ivan Moshkov and Igor Gitman},
booktitle={2nd AI for Math Workshop @ ICML 2025},
year={2025},
url={https://openreview.net/forum?id=8LhnmNmUDb}
}
附加信息:
部署地区:
全球<br>
使用场景:<br>
此模型面向从事竞争性数学、代码和科学问题研究的开发者和研究人员。它仅通过监督微调进行训练,以在基准测试中取得优异成绩。<br>
发布日期:<br>
Huggingface [07/16/2025] 通过 https://huggingface.co/nvidia/OpenReasoning-Nemotron-1.5B/ <br>
参考:
- [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
- [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
- [2504.16891] AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset <br>
模型架构:<br>
架构类型:稠密仅解码器 Transformer 模型 网络架构:Qwen-1.5B-Instruct <br> 此模型基于 Qwen2.5-1.5B-Instruct 开发,具有 1.5B 模型参数。<br>
OpenReasoning-Nemotron-1.5B 基于 Qwen2.5-1.5B-Instruct 开发,具有 1.5B 模型参数。<br>
OpenReasoning-Nemotron-7B 基于 Qwen2.5-7B-Instruct 开发,具有 7B 模型参数。<br>
OpenReasoning-Nemotron-14B 基于 Qwen2.5-14B-Instruct 开发,具有 14B 模型参数。<br>
OpenReasoning-Nemotron-32B 基于 Qwen2.5-32B-Instruct 开发,具有 32B 模型参数。<br>
输入:<br>
输入类型: 文本 <br> 输入格式: 字符串 <br> 输入参数: 一维 (1D) <br> 与输入相关的其他属性: 训练支持最多 64,000 个输出 token <br>
输出:<br>
输出类型: 文本 <br> 输出格式: 字符串 <br> 输出参数: 一维 (1D) <br> 与输出相关的其他属性: 训练支持最多 64,000 个输出 token <br>
我们的 AI 模型设计用于和/或优化为在 NVIDIA GPU 加速系统上运行。通过利用 NVIDIA 的硬件(如 GPU 核心)和软件框架(如 CUDA 库),该模型相比仅使用 CPU 的解决方案实现了更快的训练和推理时间。<br>
软件集成:<br>
- 运行时引擎:NeMo 2.3.0 <br>
- 推荐硬件微架构兼容性:<br> NVIDIA Ampere <br> NVIDIA Hopper <br>
- 首选/支持的操作系统:Linux <br>
模型版本:
1.0 (7/16/2025) <br> OpenReasoning-Nemotron-32B<br> OpenReasoning-Nemotron-14B<br> OpenReasoning-Nemotron-7B<br> OpenReasoning-Nemotron-1.5B<br>
训练和评估数据集:<br>
训练数据集:
OpenReasoning-Nemotron-1.5B 的训练语料库包含来自 OpenCodeReasoning 数据集、OpenCodeReasoning-II、OpenMathReasoning 的问题,以及来自 Llama-Nemotron-Post-Training-Dataset 的合成科学问题。所有回复均使用 DeepSeek-R1-0528 生成。我们还包含了来自 Llama-Nemotron-Post-Training-Dataset 的指令遵循和工具调用数据,未做修改。
数据收集方法:混合:自动化、人工、合成 <br> 标注方法:混合:自动化、人工、合成 <br> 属性:来自 OpenCodeReasoning 问题的 500 万个 DeepSeek-R1-0528 生成的回复 <br>
评估数据集:
我们使用以下基准测试对模型进行全面评估。
数学
- AIME 2024/2025 <br>
- HMMT 2025年2月 <br>
代码
- LiveCodeBench <br>
- SciCode <br>
科学
- GPQA <br>
- MMLU-PRO <br>
- HLE <br>
数据收集方法:混合:自动化、人工、合成 <br> 标注方法:混合:自动化、人工、合成 <br>
推理:
加速引擎: vLLM, Tensor(RT)-LLM <br> 测试硬件 NVIDIA H100-80GB <br>
伦理考量:
NVIDIA 认为可信 AI 是一项共同责任,我们已建立政策和实践以支持广泛的 AI 应用开发。当根据我们的服务条款下载或使用时,开发者应与其内部模型团队合作,确保此模型满足相关行业和用例的要求,并解决不可预见的产品滥用问题。
有关此模型的伦理考量的更多详细信息,请参阅 Model Card++ 的可解释性、偏见、安全与隐私子卡片。
请在此处报告模型质量、风险、安全漏洞或 NVIDIA AI 疑虑 链接。
Prince-1/OpenReasoning-Nemotron-1.5B
作者 Prince-1
创建时间: 2025-08-04 13:07:43+00:00
更新时间: 2025-08-04 13:08:05+00:00
在 Hugging Face 上查看