说明文档
德语 BERT

概述
语言模型: bert-base-cased
语言: 德语
训练数据: Wiki、OpenLegalData、新闻(约 12GB)
评估数据: Conll03(NER)、GermEval14(NER)、GermEval18(分类)、GNAD(分类)
基础设施:1x TPU v2
发布时间:2019年6月14日
2020年4月3日更新:我们更新了 deepset s3 上的词汇表文件,以符合标点符号分词的默认设置。 有关详情请参阅相关的 FARM 问题。如果您想使用旧词汇表,我们还上传了一个 "deepset/bert-base-german-cased-oldvocab" 模型。
详情
- 我们使用 Google 的 Tensorflow 代码在单个云 TPU v2 上进行训练,采用标准设置。
- 我们训练了 810,000 步,批大小为 1024,序列长度为 128,以及 30,000 步,序列长度为 512。训练耗时约 9 天。
- 训练数据我们使用了最新的德语 Wikipedia dump(6GB 原始文本文件)、OpenLegalData dump(2.4 GB)和新闻文章(3.6 GB)。
- 我们使用定制的脚本清理了数据dump,并使用 spacy v2.1 进行句子分割。为了创建 tensorflow 记录,我们使用了推荐的 sentencepiece 库来创建词片词汇表,并使用 tensorflow 脚本将文本转换为 BERT 可用的数据。
有关更多详情,请访问 https://deepset.ai/german-bert
超参数
batch_size = 1024
n_steps = 810_000
max_seq_len = 128(后续为 512)
learning_rate = 1e-4
lr_schedule = LinearWarmup
num_warmup_steps = 10_000
性能
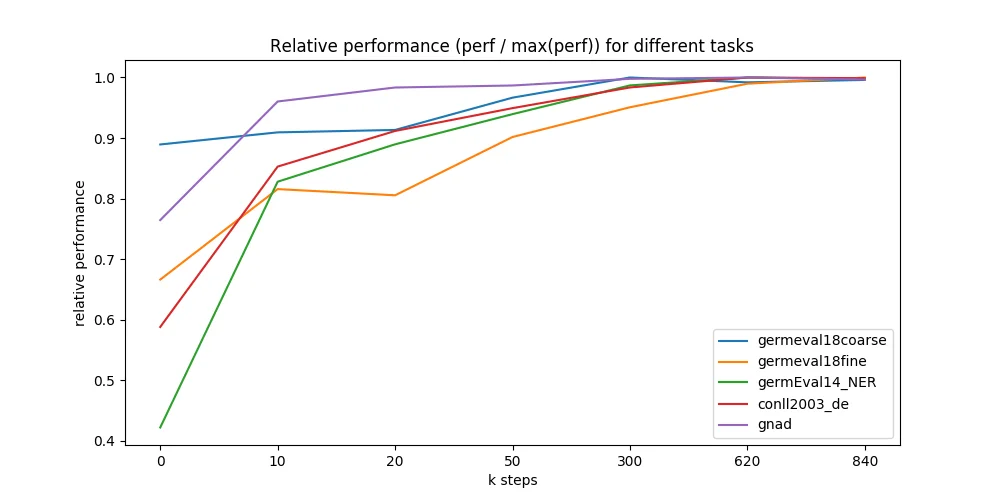
在训练过程中,我们监控了损失值,并在以下德语数据集上评估了不同的模型检查点:
- germEval18Fine:多类情感分类的宏 F1 分数
- germEval18coarse:二元情感分类的宏 F1 分数
- germEval14:NER 的序列 F1 分数(文件名 deuutf.*)
- CONLL03:NER 的序列 F1 分数
- 10kGNAD:文档分类的准确率
即使没有进行彻底的超参数调优,我们观察到学习过程相当稳定,特别是对于我们的德语模型。使用不同种子的多次重启产生了非常相似的结果。

我们进一步评估了预训练 9 天期间的不同数据点,并惊讶地发现模型能够如此快速地收敛到最佳可达性能。我们在 7 个不同的模型检查点上运行了所有 5 个下游任务——这些检查点取自 0 到 840,000 训练步(见下图 x 轴)。大多数检查点取自我们预期性能变化最大的训练早期。有趣的是,即使是一个随机初始化的 BERT,仅在带标签的下游数据集上进行训练也能达到良好的性能(蓝线,GermEval 2018 粗粒度任务,795 kB 训练集大小)。
作者
- Branden Chan:
branden.chan [at] deepset.ai - Timo Möller:
timo.moeller [at] deepset.ai - Malte Pietsch:
malte.pietsch [at] deepset.ai - Tanay Soni:
tanay.soni [at] deepset.ai
关于我们
![]()
我们通过开源将 NLP 带给行业!
我们的重点:行业特定语言模型和大规模问答系统。
我们的部分工作:
google-bert/bert-base-german-cased
作者 google-bert
创建时间: 2022-03-02 23:29:04+00:00
更新时间: 2024-02-19 11:03:41+00:00
在 Hugging Face 上查看