说明文档
nomic-embed-text-v1.5: 使用套娃表征学习实现可调整大小的生产级文本嵌入
博客 | 技术报告 | AWS SageMaker | Nomic 平台
激动人心的更新!:现在 nomic-embed-text-v1.5 支持多模态了!nomic-embed-vision-v1.5 已与 nomic-embed-text-v1.5 的嵌入空间对齐,这意味着任何文本嵌入都是多模态的!
使用方法
重要提示:文本提示必须包含一个任务指令前缀,用于指示模型正在执行哪个任务。
例如,如果你正在实现 RAG 应用程序,你需要将文档嵌入为 search_document: <text here>,将用户查询嵌入为 search_query: <text here>。
任务指令前缀
search_document
用途:将文本作为数据集中的文档进行嵌入
此前缀用于将文本作为文档进行嵌入,例如作为 RAG 索引中的文档。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
sentences = ['search_document: TSNE 是由 Laurens van Der Maaten 创建的降维算法']
embeddings = model.encode(sentences)
print(embeddings)
search_query
用途:将文本作为待回答的问题进行嵌入
此前缀用于将文本作为问题进行嵌入,这些问题可由数据集中的文档来解答,例如作为 RAG 应用程序需要回答的查询。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
sentences = ['search_query: Who is Laurens van Der Maaten?']
embeddings = model.encode(sentences)
print(embeddings)
clustering
用途:嵌入文本以便将它们分组到聚类中
此前缀用于嵌入文本,以便将它们分组到聚类中、发现共同主题或消除语义重复。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
sentences = ['clustering: the quick brown fox']
embeddings = model.encode(sentences)
print(embeddings)
classification
用途:嵌入文本以便对它们进行分类
此前缀用于将文本嵌入为向量,这些向量将用作分类模型的特征。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
sentences = ['classification: the quick brown fox']
embeddings = model.encode(sentences)
print(embeddings)
Sentence Transformers
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
matryoshka_dim = 512
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
embeddings = model.encode(sentences, convert_to_tensor=True)
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
Transformers
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', trust_remote_code=True, safe_serialization=True)
model.eval()
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
+ matryoshka_dim = 512
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
+ embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
+ embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
该模型原生支持将序列长度扩展到超过 2048 个令牌。为此:
- tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
+ tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', model_max_length=8192)
- model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', trust_remote_code=True)
+ model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', trust_remote_code=True, rotary_scaling_factor=2)
Transformers.js
import { pipeline, layer_norm } from '@huggingface/transformers';
// Create a feature extraction pipeline
const extractor = await pipeline('feature-extraction', 'nomic-ai/nomic-embed-text-v1.5');
// Define sentences
const texts = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?'];
// Compute sentence embeddings
let embeddings = await extractor(texts, { pooling: 'mean' });
console.log(embeddings); // Tensor of shape [2, 768]
const matryoshka_dim = 512;
embeddings = layer_norm(embeddings, [embeddings.dims[1]])
.slice(null, [0, matryoshka_dim])
.normalize(2, -1);
console.log(embeddings.tolist());
Nomic API
使用 Nomic Embed 最简单的方式是通过 Nomic 嵌入 API。
使用 nomic Python 客户端生成嵌入非常简单:
from nomic import embed
output = embed.text(
texts=['Nomic Embedding API', '#keepAIOpen'],
model='nomic-embed-text-v1.5',
task_type='search_document',
dimensionality=256,
)
print(output)
更多信息,请参阅 API 参考文档
Infinity
与 Infinity 配合使用。
docker run --gpus all -v $PWD/data:/app/.cache -e HF_TOKEN=$HF_TOKEN -p \"7997\":\"7997\" \
michaelf34/infinity:0.0.70 \
v2 --model-id nomic-ai/nomic-embed-text-v1.5 --revision \"main\" --dtype float16 --batch-size 8 --engine torch --port 7997 --no-bettertransformer
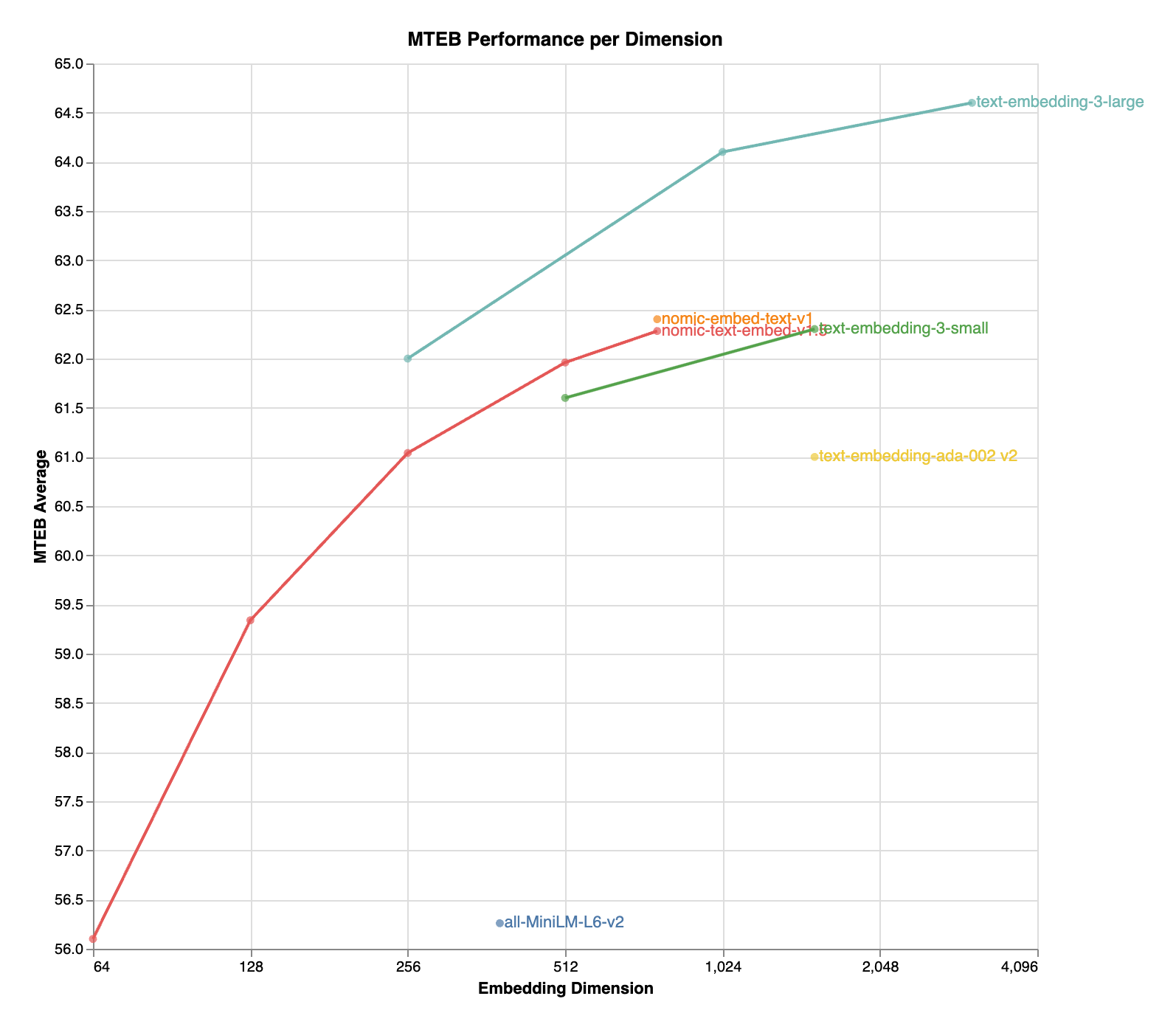
调整维度
nomic-embed-text-v1.5 是 Nomic Embed 的改进版本,它利用了 套娃表征学习,让开发者能够灵活地权衡嵌入大小与性能之间的取舍。
| 名称 | 序列长度 | 维度 | MTEB |
|---|---|---|---|
| nomic-embed-text-v1 | 8192 | 768 | 62.39 |
| nomic-embed-text-v1.5 | 8192 | 768 | 62.28 |
| nomic-embed-text-v1.5 | 8192 | 512 | 61.96 |
| nomic-embed-text-v1.5 | 8192 | 256 | 61.04 |
| nomic-embed-text-v1.5 | 8192 | 128 | 59.34 |
| nomic-embed-text-v1.5 | 8192 | 64 | 56.10 |
训练
点击下方 Nomic Atlas 地图,可视化我们对比预训练数据的 500 万样本!

我们使用多阶段训练流程来训练嵌入器。从长上下文 BERT 模型 开始,第一个无监督对比阶段在从弱相关文本对生成的数据集上进行训练,例如来自 StackExchange 和 Quora 等论坛的问答对、来自 Amazon 评论的标题-正文对,以及来自新闻文章的摘要。
在第二个微调阶段,利用更高质量的标注数据集,如来自网络搜索的搜索查询和答案。数据筛选和困难样本挖掘在这一阶段至关重要。
更多详细信息,请参阅 Nomic Embed 技术报告 和对应的博客文章。
训练模型用的训练数据已完整发布。更多详细信息,请参阅 contrastors 仓库
加入 Nomic 社区
- Nomic: https://nomic.ai
- Discord: https://discord.gg/myY5YDR8z8
- Twitter: https://twitter.com/nomic_ai
引用
如果您发现该模型、数据集或训练代码有用,请引用我们的工作
@misc{nussbaum2024nomic,
title={Nomic Embed: Training a Reproducible Long Context Text Embedder},
author={Zach Nussbaum and John X. Morris and Brandon Duderstadt and Andriy Mulyar},
year={2024},
eprint={2402.01613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
nomic-ai/nomic-embed-text-v1.5
作者 nomic-ai
创建时间: 2024-02-10 06:32:35+00:00
更新时间: 2025-07-21 17:44:14+00:00
在 Hugging Face 上查看