说明文档
gelectra-base-germanquad (ONNX)
这是 deepset/gelectra-base-germanquad 的 ONNX 版本。它通过 此 Hugging Face Space 自动转换并上传。
使用 Transformers.js
请参阅 question-answering 的管道文档:https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.QuestionAnsweringPipeline
gelectra-base 抽取式问答模型
概述
语言模型: gelectra-base-germanquad
语言: 德语
训练数据: GermanQuAD 训练集(约 12MB)
评估数据: GermanQuAD 测试集(约 5MB)
基础设施:1x V100 GPU
代码: 参见使用 Haystack 构建的抽取式问答管道示例
发布日期:2021年4月21日
详情
- 我们以 gelectra-base 模型为基础,训练了一个德语问答模型。
- 数据集为 GermanQuAD,这是一个新的德语数据集,由我们手工标注并在线发布。
- 训练数据集采用单向标注,包含 11518 个问题和 11518 个答案;测试数据集采用三向标注,共有 2204 个问题和 2204·3−76 = 6536 个答案(我们移除了 76 个错误答案)。
更多详情及 SQuAD 格式的数据集下载,请参见 https://deepset.ai/germanquad。
超参数
batch_size = 24
n_epochs = 2
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
用法
在 Haystack 中使用
Haystack 是一个 AI 编排框架,用于构建可定制、可生产的 LLM 应用程序。您可以在 Haystack 中使用此模型对文档进行抽取式问答。 使用 Haystack 加载并运行模型:
# 运行 pip install haystack-ai "transformers[torch,sentencepiece]" 后
from haystack import Document
from haystack.components.readers import ExtractiveReader
docs = [
Document(content="Python is a popular programming language"),
Document(content="python ist eine beliebte Programmiersprache"),
]
reader = ExtractiveReader(model="deepset/gelectra-base-germanquad")
reader.warm_up()
question = "What is a popular programming language?"
result = reader.run(query=question, documents=docs)
# {'answers': [ExtractedAnswer(query='What is a popular programming language?', score=0.5740374326705933, data='python', document=Document(id=..., content: '...'), context=None, document_offset=ExtractedAnswer.Span(start=0, end=6),...)]}
如需查看可扩展到大量文档的完整抽取式问答管道示例,请参阅相应的 Haystack 教程。
在 Transformers 中使用
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/gelectra-base-germanquad"
# a) 获取预测结果
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) 加载模型和分词器
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
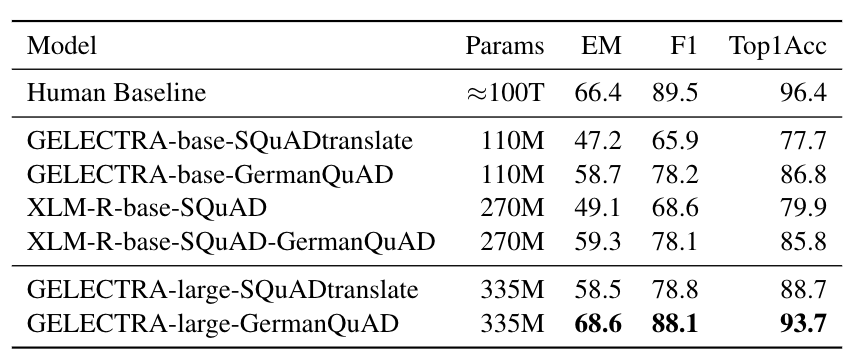
性能
我们在 GermanQuAD 测试集上评估了抽取式问答的性能。
模型类型和训练数据已包含在模型名称中。
对于 XLM-Roberta 的微调,我们使用英语 SQuAD v2.0 数据集。
GELECTRA 模型先在 SQuAD v1.1 的德语翻译版本上进行预热启动,然后在 GermanQuAD 上进行微调。
人工基线是通过在三向测试集上取一个答案作为预测,另外两个作为真实值计算得出的。
作者
Timo Möller: timo.moeller@deepset.ai
Julian Risch: julian.risch@deepset.ai
Malte Pietsch: malte.pietsch@deepset.ai
关于我们
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3"> <div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center"> <img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/> </div> <div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center"> <img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/> </div> </div>
deepset 是可生产的开源 AI 框架 Haystack 背后的公司。
我们的其他工作:
- 蒸馏版 roberta-base-squad2(又称 "tinyroberta-squad2")
- 德语 BERT、GermanQuAD 和 GermanDPR、德语嵌入模型
- deepset Cloud、deepset Studio
联系我们并加入 Haystack 社区
<p>欲了解更多关于 Haystack 的信息,请访问我们的 <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> 仓库和 <strong><a href="https://docs.haystack.deepset.ai">文档</a></strong>。
我们还有一个<strong><a class="h-7" href="https://haystack.deepset.ai/community">对所有人开放的 Discord 社区!</a></strong></p>
Twitter | LinkedIn | Discord | GitHub Discussions | 网站 | YouTube
顺便说一下:我们在招人!
onnx-community/gelectra-base-germanquad-ONNX
作者 onnx-community
创建时间: 2026-01-16 17:10:34+00:00
更新时间: 2026-01-16 17:10:44+00:00
在 Hugging Face 上查看